

基于短波近红外高光谱技术的塑料分类识别应用实践
研究背景与挑战
随着塑料制品的广泛应用,废弃塑料数量迅速增加,但不同聚合物(如PET、PP、PE等)混杂严重,制约了高值化回收利用。传统人工或密度分选方法效率低且精度有限,而短波近红外(SWIR)高光谱相机能够获取材料在900–1700 nm范围内的分子振动特征,实现无损、快速识别,已成为智能分选的重要技术手段。研究表明,该技术结合机器学习算法可实现90%以上甚至接近100%的分类精度,为塑料自动化分拣与循环经济提供关键支撑。
尽管SWIR高光谱在塑料识别中表现优异,但实际应用仍面临多重挑战。首先,高光谱数据维度高、处理复杂,对算法与计算能力要求较高,增加系统成本;其次,实际废塑料常存在污染、老化及颜色差异(如黑色塑料),会显著干扰光谱特征,导致识别精度下降;此外,不同塑料光谱特征相似(如HDPE与LDPE),易产生混淆;最后,设备成本与工业在线应用的稳定性仍需优化。因此,如何实现低成本、高鲁棒性和快速处理成为当前研究重点。

人工分选废弃塑料的场景
ATH1010R-17在塑料分选中的应用
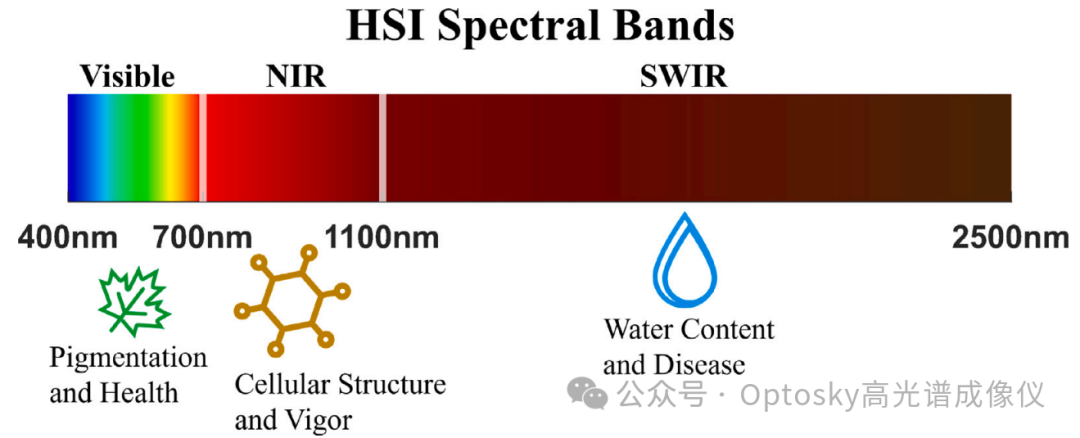
短波红外
在该实验研究中,选用奥谱天成ATH1010R-17短波近红外高光谱相机作为核心数据采集设备。该相机采用透射光栅分光方式,光谱覆盖范围为900–1700 nm,具备高光谱分辨能力(典型优于6 nm),同时支持高速推扫成像模式,能够实现对动态传送带样品的连续扫描,满足工业在线分选需求。此外,ATH1010R-17具备良好的信噪比与稳定性,适用于复杂环境下的塑料材质识别与分析。
实验中共选取9种常见塑料样本,包括PET、PE、PVC、PP、PS、PC、POM、ABS及PA等典型工程塑料。训练样本统一制备为10 cm ×4 cm ×4 mm的标准片材,以保证建模数据的一致性;验证样本则引入不同颜色(含黑色塑料)、不同表面处理(磨砂、光滑)及不规则形状,以更贴近实际垃圾分选场景中的复杂工况。

在数据采集过程中,通过ATH1010R-17获取各类塑料样本的高光谱图像,并进行标准黑白校正处理,以消除暗电流噪声及光照不均带来的影响,提高光谱数据的准确性与可比性。针对单次视场范围有限的问题,采用多帧图像拼接方式获取完整样本图像,随后进行ROI(感兴趣区域)提取与平均光谱计算,为后续基于机器学习或深度学习的塑料分类模型构建提供高质量数据基础。

数据预处理与模型构建
为提升奥谱天成ATH1010R-17采集数据的质量与可用性,研究团队对提取的高光谱数据进行了系统化预处理。首优良行光谱裁剪,选取信息量更丰富的1100–1650 nm波段,以降低冗余数据干扰;随后采用中值滤波与Savitzky-Golay(SG)平滑方法,有效去除随机噪声并保留光谱特征形状;在此基础上引入标准正态变量变换(SNV),以削弱样品表面粗糙度及散射效应带来的影响;最后通过归一化处理,将不同样本的反射率统一到同一尺度范围。经过多步预处理后,光谱曲线特征更加平滑清晰,不同塑料之间的差异被有效放大,为后续建模提供了可靠的数据基础。
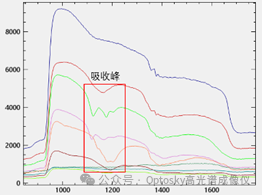
不同塑料的的吸收峰位置
在模型构建方面,研究团队采用随机森林(Random Forest)算法进行塑料分类识别。该方法通过构建多棵决策树并进行集成学习,能够有效处理高维光谱数据并降低过拟合风险。同时,利用袋外误差(OOB)对模型进行评估,并通过调节树的数量、最大深度及特征子集数量等参数进行优化。实验结果表明,基于ATH1010R-17采集数据训练得到的随机森林模型在复杂验证样本中表现稳定,对多种塑料类型具有良好的区分能力,整体分类准确率可达97%以上,体现出较强的鲁棒性与工程应用价值。
可视化分类效果
为检验模型在实际场景中的泛化能力,研究团队将训练完成的随机森林模型应用于多种复杂摆放状态下的高光谱图像,包括平铺、堆叠及杂乱混合等情况。通过颜色编码对分类结果进行可视化,结果表明,采用ATH1010R-17采集的高光谱数据能够在不同工况下实现清晰、稳定的分类显示。
在各类验证场景中,随机森林模型均表现出良好的稳定性与鲁棒性,尤其在样本边缘区域识别及阴影干扰处理方面具有较优表现。研究结果表明,ATH1010R-17获取的高光谱数据结合合理的数据预处理与模型算法,能够实现对不同颜色、形状及表面状态塑料的有效识别,具备良好的工程应用潜力。

原始数据(左)随机森林分类效果(右)
产品推荐
ATH1010R


产品特点
光谱范围:0.9~ 1.7 μm
探测器:InGaAs 探测器
波段通道数:640
空间通道数:512
光谱分辨率:5.5nm
探测器原始分辨率:640 X 512
数据格式兼容 :ENVI
体积 :370mm x 85mm x 95mm
重量: 小于0.8Kg

